Google : Bruxelles enquête sur la rétrogradation des contenus de certains médias
Publireportages, publicités natives ou spam, c'est pas la même chose ?

Dans son moteur de recherche, Google a décidé de rétrograder des publications sponsorisées publiées sur les sites de certains médias, les considérant comme du spam. La Commission européenne vient d’ouvrir une enquête sur le sujet pour vérifier que cette démarche respecte le DMA et que Google n’utilise pas ce filtre pour protéger ses parts de marché dans la publicité en ligne.
La Commission européenne ouvre une nouvelle enquête sur les pratiques de Google. Alors qu’elle a récemment infligé une amende de 3 milliards d’euros à l’entreprise pour avoir enfreint les règles de la concurrence dans le domaine de la publicité, l’organe exécutif de l’Union européenne s’intéresse à la rétrogradation de contenus de certains médias dans le moteur de recherche.
Elle cherche à vérifier que Google applique bien « des conditions d’accès équitables, raisonnables et non discriminatoires aux sites web des éditeurs sur Google Search », explique-t-elle dans un communiqué, en précisant que c’est une obligation imposée par la législation sur les marchés numériques (le DMA).
Google considère depuis un an et demi certains publireportages ou publicités natives comme du spam
Tout part d’une mise à jour par Google, en mars 2024, de ses règles concernant le spam pour son moteur de recherche.
On peut y lire notamment que, depuis, l’entreprise considère comme des « liens toxiques » les « publireportages ou publicités natives pour lesquels une rémunération est perçue contre des articles contenant des liens qui améliorent le classement, ou des liens avec du texte d’ancrage optimisé dans des articles, des articles d’invités, ou des communiqués de presse diffusés sur d’autres sites ».
Dans son argumentaire pour justifier cette mise à jour, Google explique sa position : « Nos Règles concernant le spam visent à contrarier les pratiques pouvant avoir un impact négatif sur la qualité des résultats de recherche Google ».
Un changement qui n’a pas plu aux lobbys de la presse européenne
Mais, comme l’expliquaient en avril dernier nos confrères de Contexte, plusieurs lobbys de la presse européenne pointaient les « pratiques de Google relatives à sa politique dite « Site Reputation Abuse » (SRA) – une mesure qui pénalise les sites web dans le classement de Google Search pour avoir coopéré avec des fournisseurs de contenu tiers, indépendamment du contrôle éditorial exercé par le site web sur ce contenu ou de sa qualité respective ».
Le même jour, l’entreprise allemande ActMeraki portait plainte auprès de la Commission sur le même sujet. « Google continue de fixer unilatéralement les règles du commerce en ligne à son avantage, en privilégiant ses propres offres commerciales et en privant les prestataires de services concurrents de toute visibilité. Il est temps d’y mettre un terme définitif », affirmait à Reuters l’avocat de l’entreprise.
Et tout le problème est là. Si les arguments de Google contre l’utilisation des publireportages ou publicités natives pour promouvoir du spam sont légitimes, l’entreprise met en place des règles concernant le marché de la publicité alors qu’elle est elle-même en position dominante sur celui-ci.
La Commission explique examiner « si les rétrogradations par Alphabet de sites web et de contenus d’éditeurs dans Google Search peuvent avoir une incidence sur la liberté des éditeurs d’exercer des activités commerciales légitimes, d’innover et de coopérer avec des fournisseurs de contenus tiers ». Elle précise que l’ouverture de son enquête « ne préjuge pas d’une constatation de non-conformité ». Elle ajoute que si elle trouve des preuves d’infractions au DMA, elle expliquera à Alphabet les mesures adéquates à prendre et qu’elle peut lui infliger une amende allant jusqu’à 10 % de son chiffre d’affaires mondial.
Dans sa déclaration sur le sujet, la vice-présidente exécutive de la Commission européenne
pour une transition propre, juste et compétitive, Teresa Ribera, est plus vindicative : « Nous sommes préoccupés par le fait que les politiques de Google ne permettent pas aux éditeurs de presse d’être traités de manière équitable, raisonnable et non discriminatoire dans ses résultats de recherche. Nous mènerons une enquête afin de nous assurer que les éditeurs de presse ne perdent pas d’importantes sources de revenus dans une période difficile pour le secteur, et que Google respecte la loi sur les marchés numériques ».
Google confirme sa position sur sa lutte anti-spam
De son côté, Google a jugé bon de publier un billet de blog pour défendre la politique anti-spam de son moteur de recherche. « L’enquête annoncée aujourd’hui sur nos efforts de lutte contre le spam est malavisée et risque de nuire à des millions d’utilisateurs européens », affirme l’entreprise. « La politique anti-spam de Google est essentielle dans notre lutte contre les tactiques trompeuses de paiement à la performance qui nuisent à la qualité de nos résultats », ajoute-t-elle.
Elle donne deux exemples d’articles sponsorisés qu’elle considère comme problématiques :

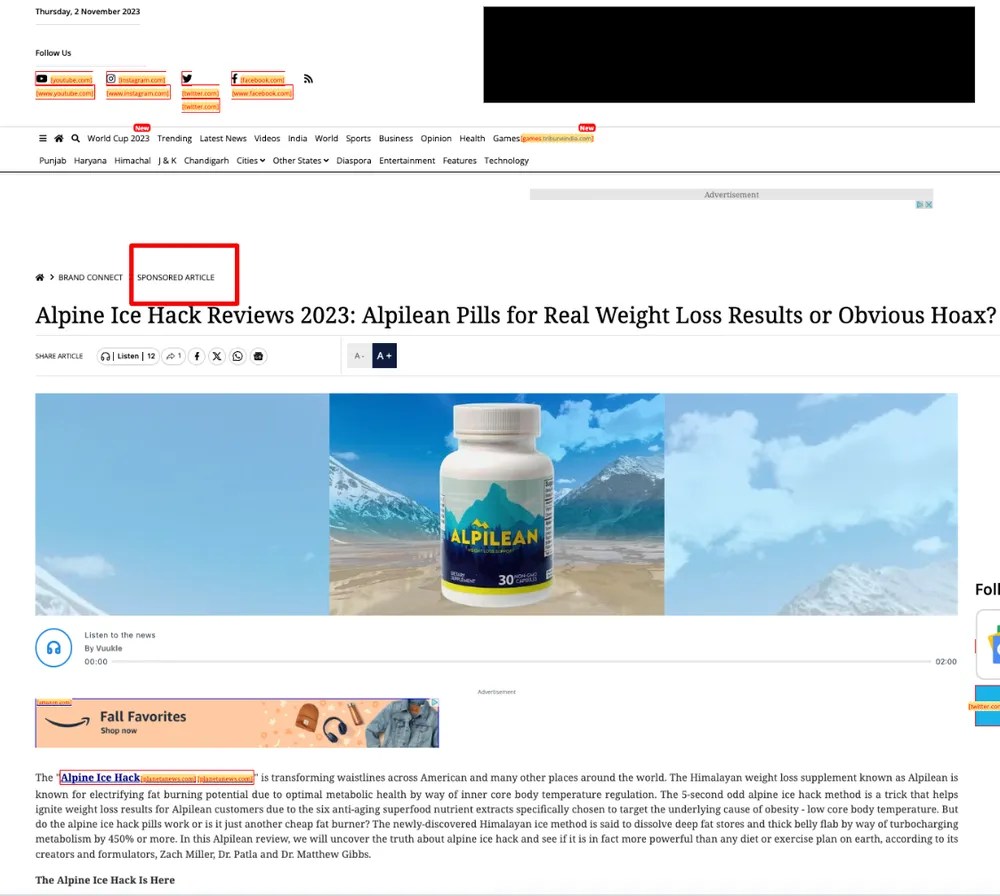
Si l’entreprise semble se soucier des spams qui polluent son moteur de recherche, rappelons qu’elle montre beaucoup moins de scrupule dans la gestion des contenus recommandés par son autre outil Discover qui met en avant, par exemple, des infox GenAI diffamantes sur du soi-disant pain cancérigène ou un faux scandale de poissons recongelés.












