Sommaire
Vérifier des programmes
Comme nous sommes sur LinuxFr.org, je devrais peut-être commencer par ceci : tous, nous passons énormément de temps à découvrir des bugs, à les comprendre, à les résoudre, et de préférence à les éviter en écrivant des tests.
Dans une formation universitaire de base en informatique, on rencontre des algorithmes, mais aussi des méthodes pour prouver que ces algorithmes terminent et répondent bien au problème posé. Les premières introduites sont typiquement les variants de boucle (montrer qu’une certaine valeur décroît à chaque itération, ce qui assure que le programme termine si elle ne peut pas décroître à l’infini), et les invariants de boucle (montrer qu’une certaine propriété vraie au début d’une boucle est préservée entre deux itérations, ce qui assure qu’elle reste encore vraie à la fin de la boucle).
On a donc, d’une part, un algorithme, implémentable sur machine, d’autre part une preuve, sur papier, que l’algorithme est correct. Mais si l’implémentation a une erreur par rapport à l’algorithme sur papier ? Et puisque nous n’arrêtons pas de nous tromper dans nos programmes, il est fort possible que nous nous trompions dans notre preuve (qui n’a jamais oublié qu’il fallait faire quelque chose de spécial dans le cas  ?).
?).
En tant que programmeurs, on peut imaginer une approche où non seulement l’algorithme est implémenté, mais sa preuve de terminaison et de correction est aussi « implémentée », c’est-à-dire encodée dans un langage qui ressemble à un langage de programmation, pour être ensuite non pas interprétée ou compilée mais vérifiée.
La vérification est un très vaste domaine de l’informatique, dont je ne suis pas spécialiste du tout, et dans lequel il existe énormément d’approches : la logique de Hoare (voir par exemple l’outil why3), qui est essentiellement un raffinement des variants et invariants de boucle, la logique de séparation spécialement conçue pour raisonner sur la mémoire mutable (voir Iris), le model checking qui se concentre sur des programmes d’une forme particulièrement simple (typiquement des systèmes de transition finis) pour en vérifier des propriétés de façon complètement automatisée, etc.
Dans cette dépêche, je vais parler d’une approche avec quelques caractéristiques particulières :
On vérifie des programmes purement fonctionnels (pas d’effets de bord, même si on peut les simuler).
Le même langage mélange à la fois les programmes et leurs preuves.
Plus précisément, le langage ne fait pas (ou peu) de distinction entre les programmes et les preuves.
Vérifier des démonstrations mathématiques
Pour se convaincre de l’ampleur que les démonstrations ont prise dans les mathématiques contemporaines, il suffit d’aller jeter un œil, par exemple, au projet Stacks : un livre de référence sur la géométrie algébrique, écrit collaborativement sur les 20 dernières années, dont l’intégrale totalise plus de 7500 pages très techniques. Ou bien la démonstration du théorème de classification des groupes finis simples : la combinaison de résultats répartis dans les dizaines de milliers de pages de centaines d’articles, et une preuve « simplifiée » toujours en train d’être écrite et qui devrait faire plus de 5000 pages. Ou bien le théorème de Robertson-Seymour, monument de la théorie des graphes aux nombreuses applications algorithmiques : 20 articles publiés sur 20 ans, 400 pages en tout. Ou bien, tout simplement, le nombre de références dans la bibliographie de la moindre thèse ou d’articles publiés récemment sur arXiv.
Inévitablement, beaucoup de ces démonstrations contiennent des erreurs. Parfois découvertes, parfois beaucoup plus tard. Un exemple assez célèbre est celui d’un théorème, qui aurait été très important s’il avait été vrai, publié en 1989 par Vladimir Voedvodsky, un célèbre mathématicien dont je vais être amené à reparler plus bas, avec Mikhail Kapranov. Comme raconté par Voedvodsky lui-même, un contre-exemple a été proposé par Carlos Simpson en 1998, mais jusqu’en 2013, Voedvodsky lui-même n’était pas sûr duquel était faux entre sa preuve et le contre-exemple !
Il y a aussi, souvent, des « trous », qui ne mettent pas tant en danger la démonstration mais restent gênants : par exemple, « il est clair que la méthode classique de compactification des espaces Lindelöf s’applique aussi aux espaces quasi-Lindelöf », quand l’auteur pense évident qu’un argument existant s’adapte au cas dont il a besoin mais que ce serait trop de travail de le rédiger entièrement. Donc, assez naturellement, un but possible de la formalisation des maths est de produire des démonstrations qui soient certifiées sans erreur (et sans trou).
Mais c’est loin d’être le seul argument. On peut espérer d’autres avantages, qui pour l’instant restent de la science-fiction, mais après tout ce n’est que le début : par exemple, on peut imaginer que des collaborations à grande échelle entre beaucoup de mathématiciens deviennent possibles, grâce au fait qu’il est beaucoup plus facile de réutiliser le travail partiel de quelqu’un d’autre s’il est formalisé que s’il est donné sous formes d’ébauches informelles pas complètement rédigées.
Brouwer-Heyting-Kolmogorov
Parmi les assistants de preuve existants, la plupart (mais pas tous) se fondent sur une famille de systèmes logiques rangés dans la famille des « théories des types ». L’une des raisons pour lesquelles ces systèmes sont assez naturels pour être utilisés en pratique est qu’en théorie des types, les preuves et les programmes deviennent entièrement confondus ou presque, ce qui rend facile le mélange entre les deux.
Mais comment est-ce qu’un programme devient une preuve, au juste ? L’idée de base est appelée interprétation de Brouwer-Heyting-Kolomogorov et veut que les preuves mathématiques se comprennent de la façon suivante :
Le moyen de base pour prouver une proposition de la forme «  et
et  » est de fournir d’une part une preuve de et une preuve de . En d’autres mots, une preuve de « et » rassemble en un même objet une preuve de et une preuve de . Mais en termes informatiques, ceci signifie qu’une preuve de « et » est une paire d’une preuve de et d’une preuve de .
» est de fournir d’une part une preuve de et une preuve de . En d’autres mots, une preuve de « et » rassemble en un même objet une preuve de et une preuve de . Mais en termes informatiques, ceci signifie qu’une preuve de « et » est une paire d’une preuve de et d’une preuve de .
De même, pour prouver « ou », on peut prouver , ou on peut prouver . Informatiquement, une preuve de « ou » va être une union disjointe : une preuve de ou une preuve de , avec un bit pour savoir dans quel cas on est.
Pour prouver « Vrai », il suffit de dire « c’est vrai » : on a une unique preuve de « Vrai ».
On ne doit pas pouvoir prouver « Faux », donc une preuve de « Faux » n’existe pas.
Et le plus intéressant : pour prouver « si alors », on suppose temporairement et on en déduit . Informatiquement, ceci doit devenir une fonction qui prend une preuve de et renvoie une preuve de .
Curry-Howard
L’interprétation de Brouwer-Heyting-Kolmogorov est informelle, et il existe plusieurs manières de la rendre formelle. Par exemple, on peut interpréter tout ceci par des programmes dans un langage complètement non-typé, ce qui s’appelle la réalisabilité.
Mais en théorie des types, on prend plutôt un langage statiquement typé pour suivre l’idée suivante : si une preuve de et est une paire d’une preuve de et d’une preuve de , alors le type des paires de et peut se comprendre comme le type des preuves de « et ». On peut faire de même avec les autres types de preuves, et ceci s’appelle la correspondance de Curry-Howard. Autrement dit, là où Brouwer-Heyting-Kolmogorov est une correspondance entre les preuves et les programmes, Curry-Howard est un raffinement qui met aussi en correspondance les propositions logiques avec les types du langage, et la vérification des preuves se confond entièrement avec le type checking.
Sur les cas que j’ai donnés, la correspondance de Curry-Howard donne :
Quantificateurs et types dépendants
La version de Curry-Howard que j’ai esquissée donne une logique dite « propositionnelle » : il n’y a que des propositions, avec des connecteurs entre elles. Mais en maths, on ne parle évidemment pas que des propositions. On parle de nombres, de structures algébriques, d’espaces topologiques, …, bref, d’objets mathématiques, et des propriétés de ces objets. Les deux types principaux de propositions qui manquent sont ce qu’on appelle les quantificateurs : « Pour tout  , … » et « Il existe tel que… ». Ici, ce qui est une évidence en logique devient moins évident, mais très intéressant, du côté des programmes.
, … » et « Il existe tel que… ». Ici, ce qui est une évidence en logique devient moins évident, mais très intéressant, du côté des programmes.
Prenons pour l’exemple le théorème des deux carrés de Fermat, qui énonce (dans l’une de ses variantes) qu’un nombre premier impair est de la forme  si et seulement s’il peut s’écrire comme somme de deux carrés parfaits. À quoi doit ressembler le type associé à cette proposition ? Par analogie avec les implications, on a envie de dire que cela devrait être une fonction, qui prend un nombre premier impair
si et seulement s’il peut s’écrire comme somme de deux carrés parfaits. À quoi doit ressembler le type associé à cette proposition ? Par analogie avec les implications, on a envie de dire que cela devrait être une fonction, qui prend un nombre premier impair  , et renvoie une preuve de l’équivalence. Problème : ce qui est à droite de l’équivalence est une proposition paramétrée par . Autrement dit, en notant le type des nombres premiers impairs, on ne veut plus un simple type fonction
, et renvoie une preuve de l’équivalence. Problème : ce qui est à droite de l’équivalence est une proposition paramétrée par . Autrement dit, en notant le type des nombres premiers impairs, on ne veut plus un simple type fonction  , mais un type fonction où le type de retour peut dépendre de la valeur passée à la fonction, noté par exemple
, mais un type fonction où le type de retour peut dépendre de la valeur passée à la fonction, noté par exemple  . Ces types qui dépendent de valeurs sont appelés types dépendants.
. Ces types qui dépendent de valeurs sont appelés types dépendants.
Dans les langages de programmation populaires, il est rare de trouver des types dépendants. Mais on en retrouve une forme faible en C avec les tableaux de longueur variable (VLA pour « variable-length arrays ») : on peut écrire
… f(int n) {
int array[n];
…
}
qui déclare un tableau dont la taille n est une expression. Néanmoins, en C, même si on dispose de ce type tableau qui est en quelque sorte dépendant, on ne peut pas écrire une fonction « int[n] f(int n) » qui renvoie un tableau dont la longueur est passée en paramètre. Plus récemment, en Rust, il existe les const generics, où des valeurs se retrouvent dans les types et où on peut écrire fn f<const n: usize>() -> [u8; n], ce qui est un vrai type dépendant, mais cette fois avec la restriction assez sévère que toutes ces valeurs peuvent être calculées entièrement à la compilation, ce qui à cause de la façon dont fonctionne ce type de calcul en Rust empêche par exemple les allocations mémoire. (Donc l’implémentation est assez différente, elle efface ces valeurs en « monomorphisant » tous les endroits où elles apparaissent.)
En théorie des types, le langage est (normalement) purement fonctionnel, donc les problèmes d’effets de bord dans les valeurs à l’intérieur des types dépendants ne se pose pas. Le type checking peut déclencher des calculs arbitrairement complexes pour calculer les valeurs qui se trouvent dans les types.
Et le « il existe », au fait, à quoi correspond-il ? Cette fois, ce n’est plus une fonction dépendante mais une paire dépendante : une preuve de « Il existe tel que  » est une paire d’une valeur et d’une preuve de . La différence avec une paire normale est que le type du deuxième élément peut dépendre de la valeur du premier élément.
» est une paire d’une valeur et d’une preuve de . La différence avec une paire normale est que le type du deuxième élément peut dépendre de la valeur du premier élément.
Comme on peut commencer à s’en douter, le fait d’avoir des types dépendants est utile pour prouver des affirmations mathématiques, mais aussi, bien qu’il puisse sembler inhabituel, pour prouver des programmes, et plus précisément pour encoder des propriétés des valeurs dans les types. Là où on aurait dans un langage moins expressif une fonction qui renvoie deux listes, avec une remarque dans la documentation qu’elles sont toujours de même taille, dans un langage avec des types dépendants, on peut renvoyer un triplet d’un entier  , d’une liste dont le type indique qu’elle est de taille , et une deuxième liste elle aussi de taille . Et là où on aurait un
, d’une liste dont le type indique qu’elle est de taille , et une deuxième liste elle aussi de taille . Et là où on aurait un deuxieme_liste[indice_venant_de_la_premiere] avec un commentaire que cela ne peut pas produire d’erreur, car les deux listes sont de même taille, on a un programme qui utilise la garantie que les deux listes sont de même taille, et le typage garantit statiquement que cette opération t[i] ne produira pas d’erreur.
Logique intuitionniste
Reprenons l’exemple du théorème des deux carrés de Fermat. Nous pouvons maintenant traduire cette proposition en un type : celui des fonctions qui prennent un nombre premier impair et renvoient une paire de :
Prouver le théorème des deux carrés de Fermat en théorie des types, c’est donner un élément (on dit plutôt « habitant ») de ce type, soit un programme dont le langage peut vérifier qu’il a ce type. Mais que fait au juste ce programme quand on l’exécute ? On voit qu’il permet notamment de calculer une décomposition d’un nombre premier impair congru à 1 modulo 4 comme somme de deux carrés.
Là, c’est le côté « programmes » qui apporte un élément moins habituel du côté « preuves » : l’exécution d’un programme va correspondre à un processus de simplification des preuves. Notamment, si on a une preuve de « si alors » et une preuve de , on peut prendre la preuve de et remplacer chaque utilisation de l’hypothèse dans la preuve de « si alors », pour obtenir une preuve de qui peut contenir de multiples copies d’une même preuve de . Cette opération de simplification du côté logique correspond naturellement au fait que la manière en théorie des types de prouver à partir d’une preuve  de
de  et d’une preuve de est tout simplement d’écrire
et d’une preuve de est tout simplement d’écrire  , et que calculer , informatiquement, se fait bien en remplaçant le paramètre de à tous les endroits où il apparaît par la valeur et à simplifier le résultat. On dit que la logique de Curry-Howard est constructive, parce qu’elle se prête à une interprétation algorithmique.
, et que calculer , informatiquement, se fait bien en remplaçant le paramètre de à tous les endroits où il apparaît par la valeur et à simplifier le résultat. On dit que la logique de Curry-Howard est constructive, parce qu’elle se prête à une interprétation algorithmique.
Mais ceci peut sembler gênant. Par exemple, il est trivial en maths « normales » de prouver que tout programme termine ou ne termine pas. Mais par Curry-Howard, une preuve que tout programme termine ou ne termine pas doit être une fonction qui prend un programme, et qui renvoie soit une preuve qu’il termine, soit une preuve qu’il ne termine pas. Autrement dit, si cette proposition censément triviale était prouvable dans Curry-Howard, on aurait un algorithme pour résoudre le problème de l’arrêt, ce qui est bien connu pour être impossible.
L’explication à cette différence tient au fait que la preuve « triviale » de cette proposition utilise une règle de déduction qui a un statut un peu à part en logique, dite règle du tiers exclu : pour n’importe quelle proposition , sans aucune hypothèse, on peut déduire « ou (non ) » (autrement dit, que est vraie ou fausse). Or cette règle n’admet pas d’interprétation évidente par Curry-Howard : le tiers exclu devrait prendre une proposition et renvoyer soit une preuve de , soit une preuve que est fausse (ce qui s’encode par « si alors Faux »), autrement dit, le tiers exclu devrait être un oracle omniscient capable de vous dire si une proposition arbitraire est vraie ou fausse, et ceci est bien évidemment impossible.
(Cela dit, si vous voulez vous faire mal à la tête, apprenez que c’est l’opérateur call/cc et pourquoi l’ajouter permet de prouver le tiers exclu. Exercice : call/cc existe dans de vrais langages, comme Scheme, pourtant on vient de voir que le tiers exclu semble nécessiter un oracle omniscient, comment expliquer cela ?)
Pour être précis, la logique sans le tiers exclu est dite intuitionniste (le terme constructive étant un peu flou, alors que celui-ci est précis). On peut faire des maths en restant entièrement en logique intuitionniste, et même si ce n’est pas le cas de l’écrasante majorité des maths, il existe tout de même un certain nombre de chercheurs qui le font, et ceci peut avoir divers intérêts. Il y a notamment l’interprétation algorithmique des théorèmes, mais aussi, de manière beaucoup plus avancée, le fait que certaines structures mathématiques (topos, ∞-topos et consorts) peuvent s’interpréter comme des sortes d’univers mathématiques alternatifs régis par les règles de la logique intuitionniste (techniquement, des « modèles » de cette logique), et que parfois il est plus simple de prouver un théorème en le traduisant à l’intérieur de l’univers et en prouvant cette version traduite de manière intuitionniste.
Pour pouvoir malgré tout raisonner en théorie des types de manière classique (par opposition à intuitionniste), il suffit de postuler le tiers exclu comme axiome. Du point de vue des programmes, cela revient à rajouter une constante qui est supposée avoir un certain type mais qui n’a pas de définition (cela peut donc rendre les programmes impossibles à exécuter, ce qui est normal pour le tiers exclu).
Quelques exemples
Si vous aviez décroché, c’est le moment de reprendre. Parlons un peu des assistants de preuve qui existent. Les plus connus sont :
Rocq, anciennement nommé Coq, développé à l’Inria depuis 1989, écrit en OCaml, sous licence LGPL 2.1. Il est assez lié à l’histoire de la théorie des types, car il a été créé par Thierry Coquand comme première implémentation du calcul des constructions, une théorie des types inventée par Coquand et devenue l’une des principales existantes. (Oui, Coq a été renommé en Rocq à cause de l’homophonie en anglais entre « Coq » et « cock ». J’apprécierais que les commentaires ne se transforment pas en flame war sur ce sujet très peu intéressant, merci.)
Lean, créé par Leonardo de Moura et développé depuis 2013 chez Microsoft Research, écrit en C++, placé sous licence Apache 2.0.
Agda, créé par Ulf Norrell en 1999, écrit en Haskell et sous licence BSD 1-clause.
D’autres que je connais moins, notamment Isabelle et F* (liste sur Wikipédia).
Pour illustrer comment peuvent fonctionner les choses en pratique, voici un exemple très simple de code en Agda :
open import Agda.Primitive using (Level)
open import Data.Product using (_×_; _,_)
swap : {ℓ₁ ℓ₂ : Level} → {P : Set ℓ₁} {Q : Set ℓ₂} → P × Q → Q × P
swap (p , q) = (q , p)
Vue comme un programme, cette fonction swap inverse simplement les deux éléments d’une paire. Vue comme une preuve, elle montre que pour toutes propositions et , si et , alors et . Comme le veut Curry-Howard, les deux ne sont pas distingués. Les types et sont eux-mêmes dans des types  avec un « niveau »
avec un « niveau »  , ceci parce que, pour des raisons logiques, il serait incohérent que le type des types soit de son propre type, donc on a un premier type de types
, ceci parce que, pour des raisons logiques, il serait incohérent que le type des types soit de son propre type, donc on a un premier type de types  , qui est lui-même de type
, qui est lui-même de type  , et ainsi de suite avec une hiérarchie infinie de niveaux appelés univers. À un niveau plus superficiel, on remarquera qu’Agda a une syntaxe qui ressemble fort à Haskell (et utilise intensivement Unicode).
, et ainsi de suite avec une hiérarchie infinie de niveaux appelés univers. À un niveau plus superficiel, on remarquera qu’Agda a une syntaxe qui ressemble fort à Haskell (et utilise intensivement Unicode).
Voilà la même chose en Rocq :
Definition swap {P Q : Prop} : P /\ Q -> Q /\ P :=
fun H => match H with conj p q => conj q p end.
La syntaxe est assez différente et ressemble plutôt à OCaml (normal, vu que Rocq est écrit en OCaml et Agda en Haskell). Mais à un niveau plus profond, on voit apparaître un type Prop dont le nom évoque furieusement les propositions. Or j’avais promis que les propositions seraient confondues avec les types, donc pourquoi a-t-on un type spécial pour les propositions ?
En réalité, pour diverses raisons, il peut être intéressant de briser l’analogie d’origine de Curry-Howard et de séparer les propositions et les autres types en deux mondes qui se comportent de façon extrêmement similaire mais restent néanmoins distincts. Notamment, un principe qu’on applique sans réfléchir en maths est que si deux propositions sont équivalentes, alors elles sont égales (extensionnalité propositionnelle), mais on ne veut clairement pas ceci pour tous les types (on peut donner des fonctions bool -> int et int -> bool, pourtant on ne veut certainement pas bool = int), donc séparer les propositions des autres permet d’ajouter l’extensionnalité propositionnelle comme axiome. (Mais il y a aussi des différences comme l'imprédicativité dans lesquelles je ne vais pas rentrer.)
Et voici encore le même code, cette fois en Lean :
def swap {P Q : Prop} : P ∧ Q → Q ∧ P :=
fun ⟨p, q⟩ => ⟨q, p⟩
À part les différences de syntaxe, c’est très similaire à Rocq, parce que Lean a aussi une séparation entre les propositions et les autres types.
Cependant, en Rocq et Lean, on peut aussi prouver la même proposition de façon différente :
Lemma swap {P Q : Prop} : P /\ Q -> Q /\ P.
Proof.
intros H. destruct H as [p q]. split.
- apply q.
- apply p.
Qed.
et
def swap {P Q : Prop} : P ∧ Q → Q ∧ P := by
intro h
have p := h.left
have q := h.right
exact ⟨q, p⟩
Avec Proof. ou by, on entre dans un mode où les preuves ne sont plus écrites à la main comme programmes, mais avec des tactiques, qui génèrent des programmes. Il existe toutes sortes de tactiques, pour appliquer des théorèmes existants, raisonner par récurrence, résoudre des inégalités, ou même effectuer de la recherche automatique de démonstration, ce qui s’avère extrêmement utile pour simplifier les preuves.
Ce mode « tactiques » permet aussi d’écrire la preuve de façon incrémentale, en faisant un point d’étape après chaque tactique pour voir ce qui est prouvé et ce qui reste à prouver. Voici par exemple ce qu’affiche Rocq après le destruct et avant le split :
P, Q : Prop
p : P
q : Q
============================
Q /\ P
Cette notation signifie que le contexte ambiant contient les variables P et Q de type Prop ainsi que p une preuve de P (donc un élément du type P) et q une preuve de Q. Le Q /\ P en dessous de la barre horizontale est le but à prouver, c’est-à-dire le type dont on cherche à construire un élément.
Agda fonctionne assez différemment : il n’y a pas de tactiques, mais il existe néanmoins un système de méta-programmation qui sert à faire de la recherche de preuves (donc contrairement à Rocq et Lean, on n’écrit pas la majeure partie des preuves avec des tactiques, mais on peut se servir d’un équivalent quand c’est utile). Pour écrire les preuves incrémentalement, on met ? dans le programme quand on veut ouvrir une sous-preuve, et Agda va faire le type-checking de tout le reste et donner le contexte à l’endroit du ?.
Quelques succès de la formalisation
En 2025, la formalisation reste très fastidieuse, mais elle a déjà eu plusieurs grands succès :
Actuellement, Lean a réussi à attirer une communauté de mathématiciens qui développent mathlib (1,1 million de lignes de code Lean au moment où j’écris), une bibliothèque de définitions et théorèmes mathématiques qui vise à être la plus unifiée possible.
Les équivalents dans d’autres assistants de preuve se développent même s’ils ne sont pas (encore) aussi gros : citons mathcomp, unimath, agda-unimath entre autres.
Un autre grand succès, dans le domaine de la vérification cette fois, est CompCert (malheureusement non-libre), qui est un compilateur C entièrement écrit en Rocq et vérifié par rapport à une spécification du C également encodée en Rocq.
La recherche en théorie des types
La théorie des types est un domaine de recherche à part entière, qui vise à étudier du point de vue logique les théories des types existantes, et à en développer de nouvelles pour des raisons à la fois théoriques et pratiques.
Historiquement, une grande question de la théorie des types est celle de comprendre à quel type doivent correspondre les propositions d’égalité. Par exemple, on veut que deux propositions équivalentes soient égales, et que deux fonctions qui prennent les mêmes valeurs soient égales, et éventuellement pour diverses raisons que deux preuves de la même proposition soient égales, mais s’il est facile d’ajouter toutes ces choses comme axiomes, il est très compliqué de les rendre prouvables sans obtenir, comme avec le tiers exclu, des programmes qui ne peuvent pas s’exécuter à cause des axiomes qui sont déclarés sans définition.
Vladimir Voedvodsky a fait une contribution majeure en proposant un nouvel axiome, appelé univalence, qui dit très sommairement que si deux types ont la même structure (on peut donner une « équivalence » entre les deux), alors ils sont en fait égaux (résumé simpliste à ne pas prendre au mot). Cet axiome est très pratique pour faire des maths parce qu’on travaille souvent avec des objets qui ont la même structure (on dit qu’ils sont isomorphes), et qui doivent donc avoir les mêmes propriétés, et cet axiome permet de les identifier (même s’il a aussi des conséquences qui peuvent paraître choquantes). Sa proposition a donné naissance à une branche appelée théorie homotopique des types, qui explore les maths avec univalence. Le prix à payer est que les types ne se comprennent plus comme de simples ensembles de valeurs (ou de preuves d’une proposition), mais comme des espaces géométriques munis de toute une structure complexe (techniquement, les égalités sont des chemins entre points, et il y a des égalités non-triviales, des égalités entre égalités, etc.), et la compréhension de ces espaces-types est fondée sur la théorie de l’homotopie. Il y a bien d’autres théories des types, avec univalence ou non : théorie cubique des types, théorie des types observationnelle, etc.
Conclusion
J’espère avoir communiqué un peu de mon enthousiasme pour le domaine (dans lequel je suis probablement parti pour démarrer une thèse). Si vous voulez apprendre un assistant de preuve, une ressource assez abordable est la série Software Foundations avec Rocq. Il existe également Theorem proving in Lean 4 et divers tutoriels Agda. Vous pouvez aussi essayer ces assistants de preuve directement dans votre navigateur : Rocq, Lean ou Agda. Et bien sûr les installer et jouer avec : Rocq, Lean, Agda.
 (
(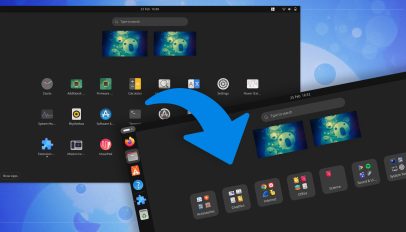 The application picker (aka app grid) in GNOME Shell is pretty perfect as it comes, showing launchers for installed apps plus the ability to rearrange them using drag and drop and create custom folders to group apps together. Some folks prefer a little more order. I’ve spotlighted a few Ubuntu app grid tweaks over the years, from one that puts app shortcuts in alphabetical order to ones which restores ‘missing’ shortcuts for apps pinned to the Ubuntu Dock. And now a new app grid helper has appeared – one sure to appeal to those with a preference for keeping things […]
The application picker (aka app grid) in GNOME Shell is pretty perfect as it comes, showing launchers for installed apps plus the ability to rearrange them using drag and drop and create custom folders to group apps together. Some folks prefer a little more order. I’ve spotlighted a few Ubuntu app grid tweaks over the years, from one that puts app shortcuts in alphabetical order to ones which restores ‘missing’ shortcuts for apps pinned to the Ubuntu Dock. And now a new app grid helper has appeared – one sure to appeal to those with a preference for keeping things […] .
. .
. .
. .
. .
. .
. .
. .
. At one time, Linux dock apps were a plentiful species, with innovative ‘panel painters’ like GNOME Do/Docky to unashamed bling-kings AWN, DockBarX and Cairo Dock. Yet it was the modest Plank which stayed the course and outlived them. Thing is, the Plank dock hasn’t seen any major development effort in years, and though it still works, there’s scope for some modern improvement, surely? One developer thinks so, and they’ve decided to do something about it. Enter, Plank Reloaded. Plank Reloaded: Plank Fork Plank Reloaded is a new fork of the original Plank Linux dock, albeit with a twist: it’s focused […]
At one time, Linux dock apps were a plentiful species, with innovative ‘panel painters’ like GNOME Do/Docky to unashamed bling-kings AWN, DockBarX and Cairo Dock. Yet it was the modest Plank which stayed the course and outlived them. Thing is, the Plank dock hasn’t seen any major development effort in years, and though it still works, there’s scope for some modern improvement, surely? One developer thinks so, and they’ve decided to do something about it. Enter, Plank Reloaded. Plank Reloaded: Plank Fork Plank Reloaded is a new fork of the original Plank Linux dock, albeit with a twist: it’s focused […] .
. .
. .
. .
. .
. .
. et renvoie deux entiers
et renvoie deux entiers  accompagnés d’une preuve que
accompagnés d’une preuve que  ,
, .
.